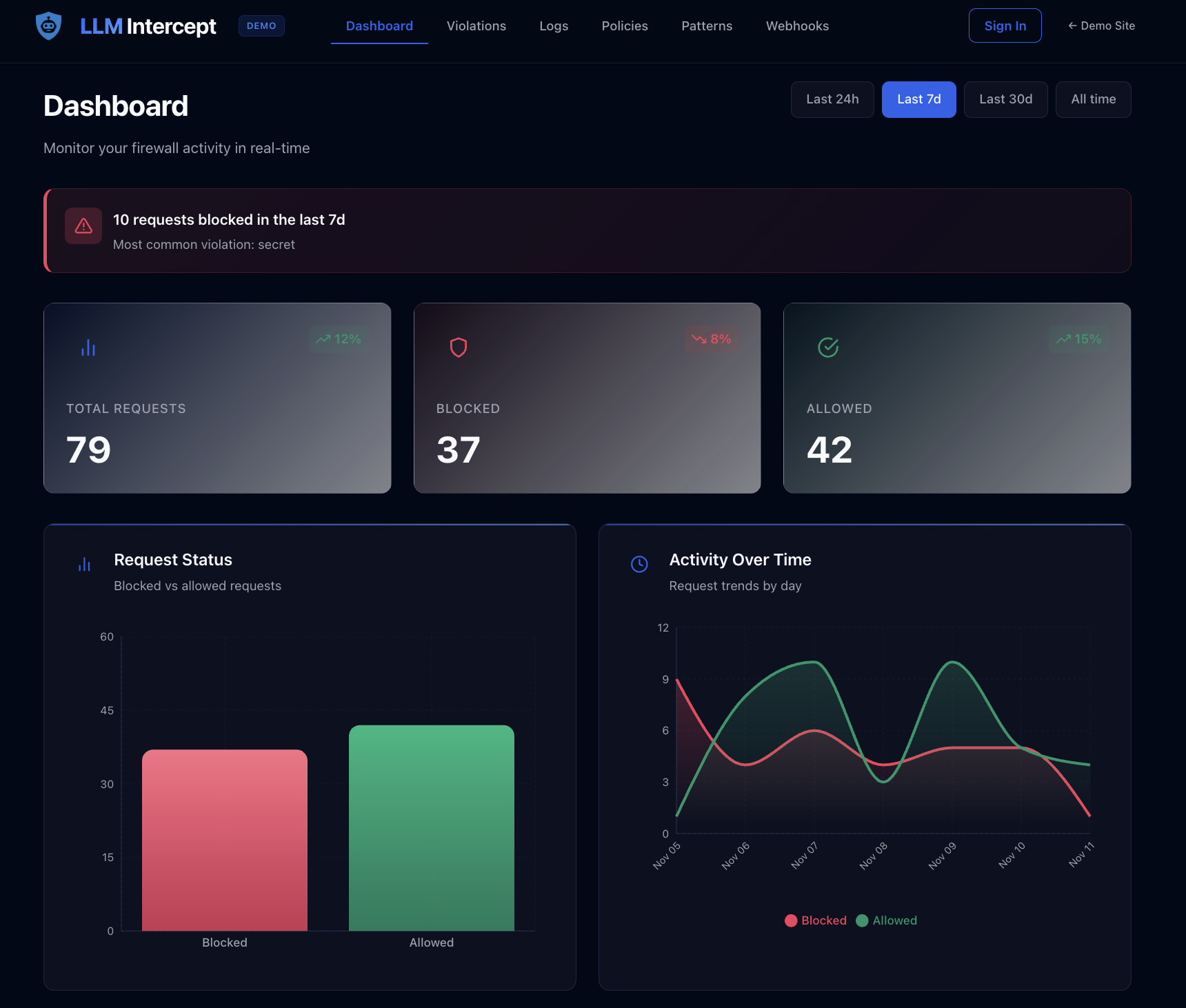
One Firewall. One Dashboard. Any Integration.
Same policies across browser, SDK, and gateway
Unified logs & violations
Real-time insights & exports
Live Dashboard Preview · Demo data
Click to open ↗